
Harnessing generative AI to address security settlement challenges
A new paper from IBM researchers explores settlement challenges and looks at how generative AI can, among other things, identify the underlying cause of an issue and rectify the errors.
Need to know
Written by:
Nibit Dutta, practice area leader – financial services support, North America
Ken Schoff, principal partner – technical specialist
Raja Basu, business architect – FSS
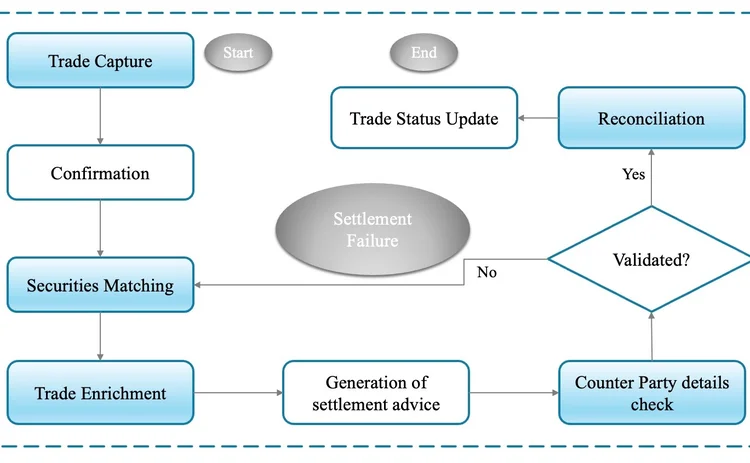
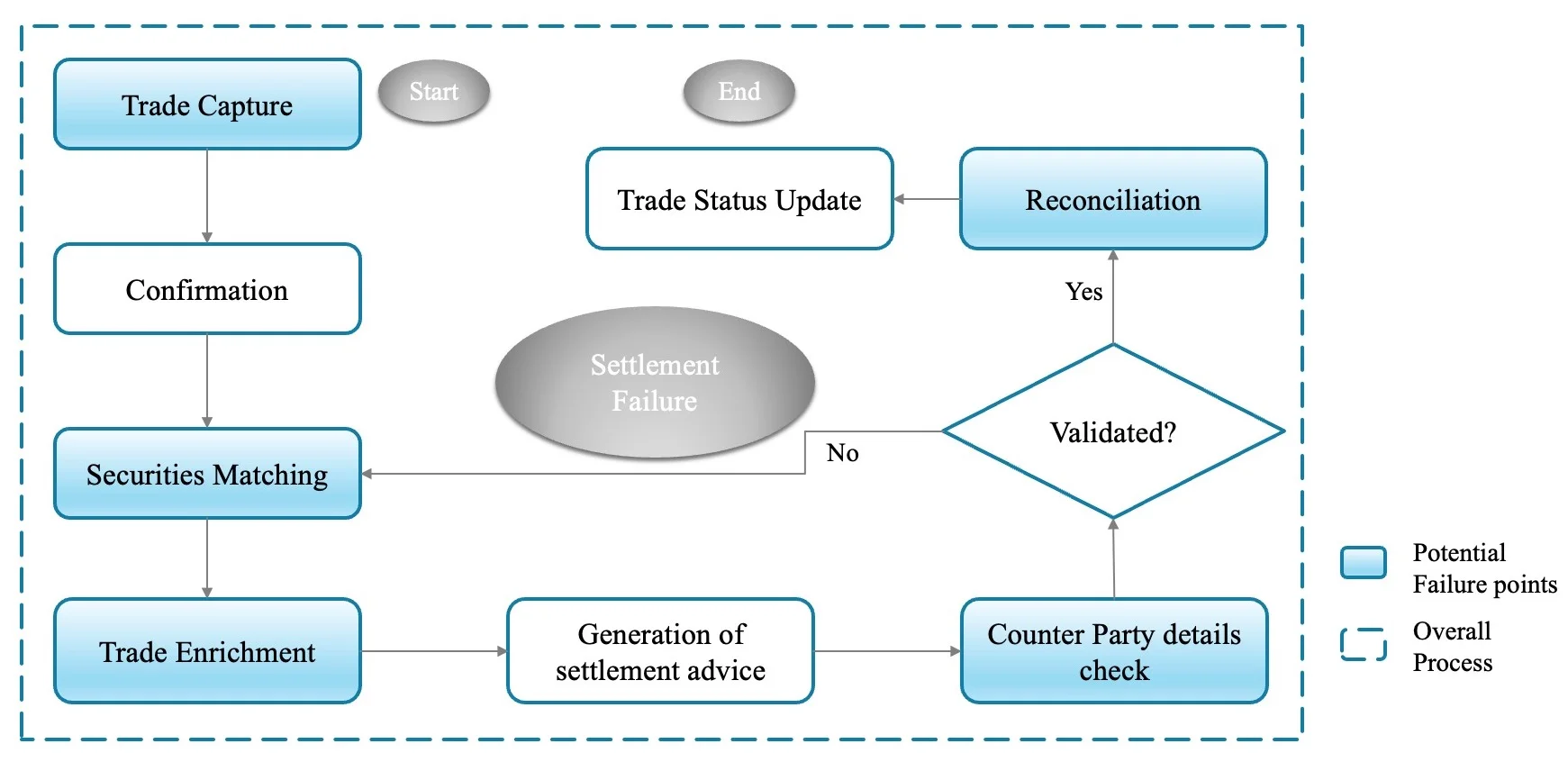
In the capital markets, the process of settling securities serves a critical function, with multiple intermediaries playing pivotal roles to ensure success. As such, the entire operation needs to go through numerous validations to check the authenticity of the participants.
However, in many instances, disjointed and heterogeneous systems complicate and prolong matters, impacting the transaction process and, overall, the settlement process. In the long run, this weakens the confidence of investors as well.
As suggested by the efficient market hypothesis, asset prices fully reflect all possible information. It is evident this theory assumes that capital markets are informationally efficient. This means that all relevant information, whether public or private, is rapidly and accurately reflected in asset prices. Therefore, it is imperative to implement changes rapidly during trading so that there is no time gap in updating the information between systems.
Improper information dissemination may lead to an inefficient market, which may be one of the major sources of security settlement failures. Let’s attempt to investigate why what appears to be a straightforward straight-through settlement process encounters such intricacies and unwanted delays.
The banking and securities industry depends heavily on books and record-keeping systems that are independently owned and maintained. These systems are typically kept separate at the legal entity level. In many cases, especially for large banks and financial institutions, this practice can extend to several separate instances. This leads to the maintenance of numerous independent records along the value chain for each security transaction.
Consequently, this not only complicates the security settlement process to complete within the stipulated timeframe, but also results in other challenges such as data duplication, redundancy in processes and operations, bilateral and sequential messaging, and reconciliation issues. To explore this further, it is imperative that we fully appreciate the significance and effects of these factors.
Data duplication: If identical data is captured in multiple systems, it can lead to conflicts, and this duplication of effort may substantially prolong the overall process. As a result, such repetitive activities can cause a significant delay in the completion of the settlement process within the stipulated timeframe.
Redundancy in processes and operations: Efforts to streamline the process represent an important phase. Typically, as the settlement deadline approaches, transaction volume experiences a sharp increase. Without adequately configured processes and appropriate infrastructure, scaling up to meet the peak time demands becomes entirely impossible.
Bilateral and sequential messaging: This refers to the process of communication and information exchange between the parties involved in the securities transactions. These messages can include trade confirmations, delivery instructions, payment details, and other relevant information. Sequential messaging adds order or sequence in which messages are exchanged between parties during the settlement process. However, if not properly planned this may result in delays, mismatched instructions, and manual errors.
Reconciliation issues: Evidently reconciliation issues can be caused by operational errors, such as data entry mismatch, system glitches, or miscommunication between parties. In cases where cash payments are involved, reconciliation problems can occur if there are discrepancies in payment amounts, currencies, or bank-specific details.
In the capital markets, there are plenty of instances we can draw from where a delay in executing security settlement on schedule wreaks havoc in the market. According to Charifa EI Otmani, director of capital market strategy at Swift, in the context of the settlement cycle, a shorter duration means that market participants have a reduced timeframe to address potential issues, particularly in areas like inventory management.
As we peruse the history of capital markets, we can readily encounter past incidents that carried considerable implications and left an imprint on investor morale. In August 1998, Russia experienced a sovereign debt default, triggering a substantial disturbance in worldwide financial markets. This default gave rise to settlement failures affecting numerous investors who held Russian bonds. Delays and ambiguities in the settlement process resulted in financial losses for those who could not reclaim the complete worth of their investments. The crisis also had a noteworthy impact on financial markets worldwide. This was one of the most extensive in history at the time and played a role in the downfall of Long-Term Capital Management (LTCM), a hedge fund in the US, necessitating a bailout of $3.6 billion, also in 1998. This subsequently caused significant ripple effects in global markets (Dungey et al, 2002).
Disconnected processes during the trade execution phase can result in inaccurate pricing, settlement postponements, and trade failures. The 2012 trading episode involving Knight Capital Group provides a pertinent example. A technical malfunction led to the firm’s automated trading system executing a multitude of unintended transactions, leading to a loss of $440 million in just a few minutes. This occurrence underscored the vital role of robust control mechanisms to prevent runaway trading algorithms and emphasized the need for post-trade reconciliation. This event reinstates the significance of simplified processes and overall process efficiency and productivity in managing the systems.
Such incidents again highlight the lack of proper process checks. In the industry, there are ongoing discussions regarding how to mitigate such uncertainties, with the aim of delivering settlements to clients promptly and avoiding penalties that can significantly dampen both client and market sentiment. Two approaches leveraging simple technology can address this concern:
Observability—primary referential data points for transaction status: (a) Design a system that allows for the central recording of a trade’s status, ensuring the existence of a validated record-keeping system; (b) allow the display of a trade’s status, irrespective of the order in which trade messages are received.
Generative AI has the capability to add value in the observability space. It can simplify the process for users to identify the underlying cause of an issue and rectify the errors. This will ensure a reduction in manual intervention, accelerate the detection and resolution of problems, and enhance the overall performance of systems. Another value addition for observability through generative AI solutions is to eliminate the reliance on tribal knowledge. It possesses the capability to analyze extensive volumes of data, process tribal knowledge, identify anomalies, and establish links between different metrics to offer insights, such as detection of the origin of an anomaly resulting from a deployment.
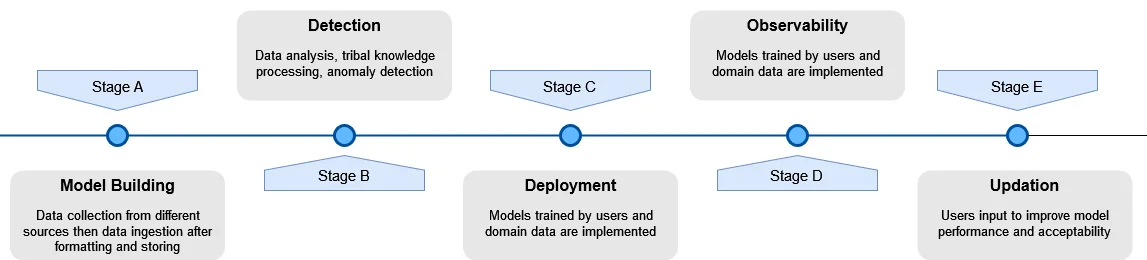
Stratified reporting structure and aggregated data visualization: (a) Create a defined categorization for positions, static data, and market data; (b) adjust the customer’s balance in accordance with incoming messages; (c) support data consolidation from individual accounts within a stratified structure consisting of multiple levels.
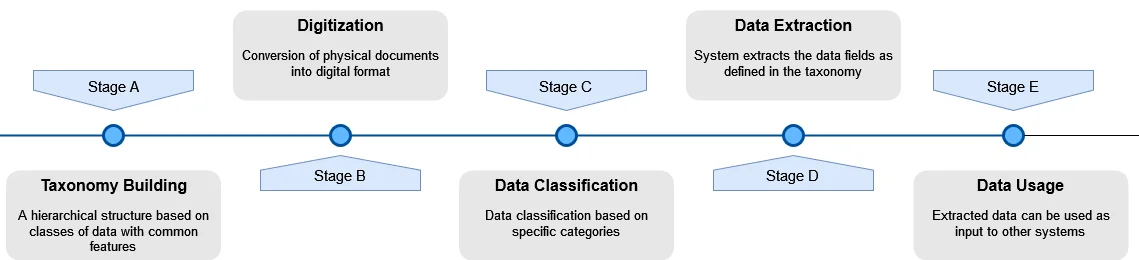
There are standard robotic process automation (RPA) software tools available in the market that have incorporated generative AI into their document and data understanding framework. This combination undoubtedly elevated the automation experience for users. The framework can help in understanding the data and extract relevant information. This will help to classify the data based on the industry, type, and storage requirements. Users can define the taxonomy where it can indicate the type of data, its usage and hierarchy more from the parent–child relationship perspectives.
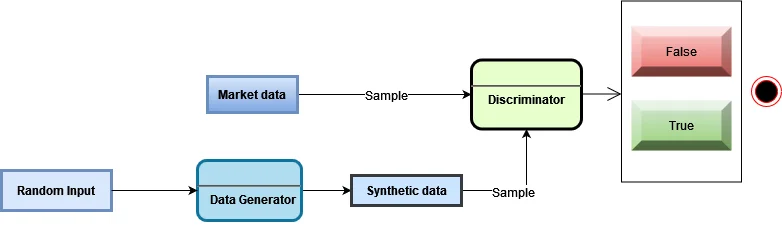
For example, security-specific data should have fields like Cusip, currency, trade type, trade date, counterparty details, etc. Optical character recognition can help capture the contract details featuring the above fields. Tools like Abbyy and Tesseract enable the OCR engine to read the content from the contract and convert the same into a machine-readable format. Once the data is correctly classified and synchronized, the system can extract relevant fields as defined in the taxonomy. There can be manual intervention to validate the data if required. After validation, the data can be used as an input to other systems. The following schematic diagram provides a visual representation of the concept discussed above:
We need to understand what is meant by data aggregation. It is the process of compiling data from different sources to present it in a summary form for a high-level analysis.
So, for a detailed analysis, a homogeneous and comprehensive dataset is required, but for many cases, data is obtained in a fragmented manner, or users get an incomplete dataset for further processing. Generative AI models, such as generative adversarial networks (GANs), can create synthetic data that closely resembles real transactional data. This synthetic data can be used to augment existing datasets and help increase the volume and diversity of data for analysis. GANs consist of a generator and a discriminator, both trained using the adversarial learning concept. The objective of GANs is to approximate the underlying distribution of actual data samples and produce new samples based on this distribution.
Once the dataset is ready, if the hierarchy structure is already in place, then data can be mapped after understanding how data at lower levels roll up to higher levels. This should be followed by aggregating data at the lower level, along with calculating relevant metrics for each lower-level entity.
Subsequently, the same should be rolled up to a higher level in the hierarchy. Such a dataset needs to be validated to ensure that the aggregated data aligns with the expected results. If there are multiple dimensions present, that should be taken care of separately so that the data integrity and authenticity is maintained. Finally, storing the aggregated data in a structured format enables easy access and fast retrieval if required. This dataset can be used as a single source of truth for reporting and visualization by creating dashboards.
As previously discussed, these methods have the potential to resolve most of the data or process-related challenges. By eliminating the need to maintain data independently at the legal entity level, the likelihood of discrepancies during reconciliation of multiple data sources will be diminished, and the risk of data duplication will also be significantly reduced. These measures will invariably produce tangible outcomes in addressing security settlement related concerns.
Only users who have a paid subscription or are part of a corporate subscription are able to print or copy content.
To access these options, along with all other subscription benefits, please contact info@waterstechnology.com or view our subscription options here: http://subscriptions.waterstechnology.com/subscribe
You are currently unable to print this content. Please contact info@waterstechnology.com to find out more.
You are currently unable to copy this content. Please contact info@waterstechnology.com to find out more.
Copyright Infopro Digital Limited. All rights reserved.
As outlined in our terms and conditions, https://www.infopro-digital.com/terms-and-conditions/subscriptions/ (point 2.4), printing is limited to a single copy.
If you would like to purchase additional rights please email info@waterstechnology.com
Copyright Infopro Digital Limited. All rights reserved.
You may share this content using our article tools. As outlined in our terms and conditions, https://www.infopro-digital.com/terms-and-conditions/subscriptions/ (clause 2.4), an Authorised User may only make one copy of the materials for their own personal use. You must also comply with the restrictions in clause 2.5.
If you would like to purchase additional rights please email info@waterstechnology.com
More on Trading Tech
ICE eyes year-end launch for Treasury clearing service
Third entrant expects Q2 comment period for new access models that address ‘done-away’ accounting hurdle
MarketAxess, S&P partnership aims for greater transparency in fixed income
CP+, MarketAxess’s AI-powered pricing engine, will receive an influx of new datasets, while S&P Global Market Intelligence integrates the tool into its suite of bond-pricing solutions.

Trading Technologies looks to ‘Multi-X’ amid vendor consolidation
The vendor’s new CEO details TT’s approach to multi-asset trading, the next generation of traders, and modern architecture.

Waters Wavelength Ep. 311: Blue Ocean’s Brian Hyndman
Brian Hyndman, CEO and president at Blue Ocean Technologies, joins to discuss overnight trading.

WatersTechnology latest edition
Check out our latest edition, plus more than 12 years of our best content.

A new data analytics studio born from a large asset manager hits the market
Amundi Asset Management’s tech arm is commercializing a tool that has 500 users at the buy-side firm.

How exactly does a private-share trading platform work?
As companies stay private for longer, new trading platforms are looking to cash in by helping investors cash out.

Accelerated clearing and settlement, private markets, the future of LSEG’s AIM market, and more
The Waters Cooler: Fitch touts AWS AI for developer productivity, Nasdaq expands tech deal with South American exchanges, National Australia Bank enlists TransFicc, and more in this week’s news roundup.
